Chris Padilla/Blog
My passion project! Posts spanning music, art, software, books, and more. Equal parts journal, sketchbook, mixtape, dev diary, and commonplace book.
- This Github conversation highlights why Jest finds an issue with compiling a seemingly unrelated package, which was my case. Remark was not used in my test directly.
- I found that Jest actually has an experimental native solution for using ECMAScript Modules
- I spent a great deal of time playing with the Jest and Babel Config, trying to get babel to transpile Remark.
- Import the dependencies
- wrap both in a
jest.mockmethod - Return the mocked result of those calls.
- Albums
- Blog Posts
- chrisdpadilla.com/spring
- chrisdpadilla.com/nextrerouting
- chrisdpadilla.com/acnm
- I'm grabbing my slugs from both albums and posts
- I'm iterating over both
- For each slug, I check if it already exists.
- If so, add it to the
recurringSlugarray - Check for an empty
reccuringSlugarray. Postis the react component rendering our page. It receives post fromgetStaticPropsgetStaticPropsis taking the slug from our url params/:slugand is looking for the matching post. Otherwise, it throws a 404.getStaticPathsis gathering all possible slugs for this page and will tell next to generate the static pages.- Checkout is a built in GitHub action that will get your current main commit.
- Cypress has their own GitHub action that takes care of setting up your app.
- I had to set
CYPRESS_BASE_URLto ensure that Cypress was looking for the correct endpoint, and not the localhost config that is set up in my cypress.config.js file. - Cypress reccomends using explicit version numbers for consistency and stability.
- You can chose which browser to test with
browser: chrome - I'm passing in my build, start, and cypress commands, though this I believe is also implicit with the Cypress GitHub action.
Caught In the ESM Migration
I was having issues with integrating packages in Jest last week and realized it's partly due to being caught in the great migration from CommonJS to ESM support:
This ESM FAQ and discussion was listed on Remark's readme. Clearly, the topic is a hot button one.
Same day, I happened to listen to Syntax's episode on ESM.
Wes and Scott highlight that, for a large part, writing ESM has been the norm for many devs thanks to build tools. Yet, technically we're still shipping CommonJS once Webpack/Babel/Parcel transpile the code.
The burden, then, is on maintainers of open source packages to wrestle with this overhead. I can see why some would opt to take the leap for simplicity and moving the language forward.
With Jest, I had my work confirmed in another way — handling this is largely a config issue.
Take aways? Why am I writing about this? Partly to document my learning, and also to share that if anyone else is trying to get up to speed in the current testing tooling, mind the gap of getting the tooling to play nice!
All said, I feel a lot less crazy knowing that it's because of a broad, industry wide gradual migration. 🙃
P.S.: Mocking is also probably the best answer to this issue from a testing methodology standpoint. It works for Uncle Dave.
Draw From Life, They Said
More sketches! 🦖

Also getting back to my roots and drawing funny Nintendo characters.


Money Jam
Jams over chords for a tune called Pay Me My Money Down. $$$
Mocking Packages in Jest
Compile Error
Last time when running my jest tests, I got an error, but it's not related to the test. The gist of the error was:
Cannot use import statement outside of a module.—in relation to a package I'm importing called remark.
Initially, I assumed it was a transpile error. Thus ensued a run down the rabbit hole of configuring Jest to transpile ESM files to CommonJS.
I could say there were some interesting finds from that tangent:
All dead ends for me.
The final recommendation I came across was to give up and find a better package.
An unsatisfactory solution at first, but it got me thinking about how I was very likely overlooking a simple solution.
Mocking
I learned first hand, logistically, the benefit of mocking to solve an implementation error. But that limitation also highlights why you mock. It's to isolate your tests to your own systems.
Nowhere along the journey of setup was there an issue with my code. It was with how the package was bundled.
But that's not even my domain to test!
This is the principle behind mocking. You want to abstract away the implementation of outside modules, packages, and systems so you can focus specifically on what unit or internal systems you're trying to test.
Implementing in Jest
Thankfully, the application of this is very straightforward with Jest.
import { getAlbums, getAllPosts } from '../lib/api';
import { remark } from 'remark';
import html from 'remark-html';
jest.mock('remark', () => ({
remark: jest.fn(() => ''),
}));
jest.mock('remark-html', () => '');
test('Verify no conflicting slugs', () => {...}In the same test file, we:
Remark is a library that my function calls don't really even need access to, so returning empty strings should do just fine.
And there we go! Jest is smart enough to know now that it doesn't even need to look inside either of my remark modules now that we have mocked versions of them.
I can now go along happily testing my slugs with each blog post and album release.
Verifying No Duplicate Routes with Jest
I'm in a situation where I just implemented dynamic routes at my site directory in Next. Essentially, I have two sources of pages:
They both are rendered on pages with slugs in this fashion:
One reason people advocate against this is that the namespace becomes cluttered. It's possible, then, to accidentally have an album and a blog title have the same slug.
Maybe a trite example since I'm a sole operation here — I should be able to catch something like that. But writing an integration test will help me sleep at night knowing that there's no way this would happen on accident.
Jest
My first step in setting up tests for the site was getting a few End-to-end checks. I've set up Cypress and written tests that verify the happy path on my site works.
Cypress can handle unit tests, but is a bit heavy handed for the solution. Jest is the long time favorite in this department, so I'm opting to bring that into the mix here.
Writing The Test
I'm modeling my configuration after the example in the Next.js repo.
With Jest running, I wrote out the test:
import { getAlbums, getAllPosts } from '../lib/api';
test('Verify no conflicting slugs', () => {
const albums = getAlbums();
const posts = getAllPosts(['slug']);
const slugs = {};
const recurringSlug = [];
const verifyUniqueSlug = (item) => {
const { slug } = item;
if (slugs[slug]) {
// Fail test
recurringSlug.push(slug);
}
slugs[slug] = true;
};
albums.forEach(verifyUniqueSlug);
posts.forEach(verifyUniqueSlug);
expect(recurringSlug).toEqual([]);
});To break it down:
Voilà! I can sleep more soundly knowing that there are no conflicting slugs.
Rerouting Dynamic Routes in Next.js
I'm a fan of short URLs. "chrisdpadilla.com/island" and "chrisdpadilla.com/cypressgithubactions" are for my albums and blog posts respectively. And they're both more satisfying than "chrisdpadilla.com/music/island" or even "chrisdpadilla.com/2022/06/03/coolblog".
They feel more elegant. It's an aesthetic choice, one that I understand goes against current SEO trends. But I like it, nonetheless!
I've already been doing this with my blog for months. However, I'm now adding album pages to my site. My gut instinct was to go with a nested route: "/music/:album", but I ultimately wanted to stick with shorter URLs.
Here we'll take a look at solving this within Next.js Dynamic Routes.
Original Setup
So, say you're like me and you have a "pages/[slug].js" file in your Next.js App. It probably looks something like this:
import { getPostBySlug, getAllPosts } from '../lib/api';
export default function Post({ post }) {
// Page component logic...
}
export async function getStaticProps({ params }) {
const post = getPostBySlug(params.slug);
if (!post) {
return {
notFound: true,
};
}
return {
props: {
post,
},
};
}
export async function getStaticPaths() {
const posts = getAllPosts(['slug']);
return {
paths: posts.map((post) => {
return {
params: {
slug: post.slug,
},
};
}),
fallback: 'blocking',
};
}No sweat with one data source. But what if we have another?
Managing Two Data Sources
It's more straightforward than you'd expect! For the most part, we're just going to add a bit more logic to these three pieces: The React component, getStaticProps, and getStaticPaths. Each will have a way to navigate between the data sources.
Starting with getStaticPaths:
export async function getStaticPaths() {
const posts = getAllPosts(['slug']);
const albums = getAlbums();
const slugs = [...albums, ...posts].map((contentObj) => contentObj.slug);
return {
paths: slugs.map((slug) => {
return {
params: {
slug,
},
};
}),
fallback: 'blocking',
};
}The only real change is merging our two sources of albums and posts.
Here's a look at getStaticProps:
export async function getStaticProps({ params }) {
const album = getAlbumBySlug(params.slug);
if (album) {
return {
props: { album },
};
}
const post = getPostBySlug(params.slug);
if (post) {
return {
props: {
post,
},
};
}
return {
notFound: true,
};
}A few simple if statements covers our bases. One performance consideration: I have fewer albums than blog posts, so I'm asking the function to check albums first for a match. Then we can search for a matching post. The nice thing, though, is that since we're generating static pages, ultimately performance will be quick for both content types when the site is built.
Lastly, we'll route our react component to two different page components:
import AlbumPage from '/components/albumPage';
import PostPage from '/components/PostPage';
export default function SlugPage({ post, album }) {
if (post) return <PostPage post={post} />;
if (album) return <AlbumPage album={album} />;
}One of the shorter React components I've ever written! We're just routing here.
I'm not needing to account for 404 cases. That's already covered with this code in getStaticProps:
return {
notFound: true,
};And that's all there is to it! A little extra traffic control for an, ultimately, cleaner site URL experience.
Construction on Plants
Studies of a Lotus Flower and leaves. 🍃
It's really fun to twist and curl thin forms!
These are part of a set of exercises from the Drawabox curriculum.


Junkyard Jam
Jamming over AC New Murder's Junkyard Jam. 🗑
Still so happy with how the vibe turned out with this track. It sounds like a leather jacket and sunglasses. 😎
By the way, you can —
Debating Stage Names
I'm gearing up to get my music on Spotify! A pretty exciting step!
But I've hit a problem: There are already 3 folks named Chris Padilla on Spotify.
It's not a new problem. In high school, I was one of 5 Chris's that played saxophone.
I'm used to having to mix up my usernames across apps and sites, but this is my whole name we're talking about!
Worth noting: It's not just a musician or an artist concern, it's a professional concern! Even Wes Bos and Scott Tolinski talked about this on Syntax.
I got this advice from Distrokid:
Ideally, if someone already has the name, you should come up with a different name. In the world of actors, for example, no two actors are allowed to have the same name as each other and both belong to SAG (the actors union). That's why Samuel L. Jackson is Samuel L. Jackson, and not Sam Jackson or Samuel Jackson -- those names were taken. If you want to look like a pro, suck it up and come up with a different name if yours is already taken.
Fair enough. So now I'm in that spot where I'm coming up with a name.
The process so far is somewhere between writing down inspirations, aesthetics I like (colors, themes, the like), and also turning to a random name generator to see what sticks.
Benefits of a Stage Name
I've liked being just "Chris Padilla" pretty much everywhere. It's kept things simple and easy for the most part. Even with music, just knowing that it's my solo project and that it can all be pointed back here.
I'm not the only Chris that does this, either!
But.
There are some exciting opportunities with stage names.
First: A stage name can encapsulate a project. Done with a set of ideas and themes? No problem! Change names and move on! Prince did it for more contractual terms, but it still worked for him!
Second: It brings an opportunity for clarity between those projects. A problem I'm starting to have is that when someone asks "What do you do?" The answer is: Software, music writing, saxophone performing, drawing, blogging, teaching. Potentially, the list could continue to grow over a lifetime! As a human being, that all can be contained within one Chris Padilla. But if you want to talk marketing terms, it gets difficult to say "Chris Padilla — Developer, Musician, Doodler, Internet Guy, Baker of Pies..." and so on.
Third: A healthy dose of separation between "The Real You" and "Public You." Derek Sivers says this well. I don't have the pleasure of being big enough for strangers on the internet to criticize me, but should I ever be, it's easier to say "Well, they're talking about Chris D Padilla. Not me, just Chris."
Fourth: There's a certain freedom that comes from a stage name. I always felt that by performing on stage, you had a chance to embody a character. To step into a person, mindset, and mood you might not otherwise channel in your day-to-day life. A stage name is just another layer of that. Online, there's no clear stage. But a name can be like putting on a super-suit in that way.
It's funny how some domains don't have that choice. Authors, speakers, most professional work — it's all on your real name for the most part. But I think there is something to be said about how we are separate from the roles we step into.
(Well drat, but that's not entirely true! R.L Stein, Lemony Snicket, Paul Creston — all Pseudonyms!)
But, Then Again
There's also the benefits of consistency! Unambiguous, less elevated and pretentious feeling, less "webby" (I'm thinking of Twitter handles and gaming tags), more personal, and the benefit of carrying any reputation with you even as you pivot and transition through domains.
Also, maybe this is more of a problem if my name were Chris Martin. There's a really famous Christ Martin already, of course.
And then, on top of that, context matters! If I'm talking about L. Armstrong, you'll know who I mean if I'm in the midst of talking about famous Jazz musicians. You won't confuse Louie Armstrong for Lance Armstrong there.
If we're talking about SEO, a quick search of "Chris Padilla Sax" will pull up my YouTube channel of Sax videos. You won't even be recommended the Wikipedia page for former Under Secretary for International Trade Christopher A. Padilla.
So, maybe it's not as much of a problem.
New Album - Meditations

Reveries on guitar. Improvising with gestures, harmonies, and melodic lines. 🧘♀️💭
What better way to start a new year than with some dreaming?
Cover art by the unbelievably talented Calvin Wong. (Web | Instagram).
🙉 Listen on Spotify — A first for me!!
Making Next.js Links Flexible
It's a little too verbose to use Next's Link component with an anchor tag each time:
<Link href={album.link}>
<a target="_blank" rel="noopener noreferrer">
Support my music by purchasing the album on Bandcamp!
</a>
</Link>There are design reasons for this. For example! It's easier to control opening a link in a new window when the anchor tag is exposed.
BUT we can do better. Here's a HOC that will check if the link is external (includes http) or internal (/music/covers):
import Link from 'next/link';
import React from 'react';
const NextLink = ({ children, ...props }) => {
let newWindowAttr = {};
if (props.href.includes('http')) {
newWindowAttr = {
target: '_blank',
rel: 'noopener noreferrer',
};
}
return (
<Link {...props}>
<a {...newWindowAttr}>{children}</a>
</Link>
);
};
export default NextLink;As a rule on my site, internal links stay in the same window, external links open in a new window. Parsing the url this way does the trick.
Then we can use it like so:
<NextLink href={album.link}>
Support my music by purchasing the album on Bandcamp!
</NextLink>A Love Letter to 2000's YouTube
I had this conversation with my sister Jenn the other day, and this post essentially came out of my mouth over the phone.
Before algorithms, video monetization, and influencers, early Youtube was totally amateur. And I loved it!
Some animators in the industry that are around my age can point to Newgrounds as the place they started messing around with their craft. (Many guests on Creative Block talk about this shared history.)
Some folks in the web development space got their start customizing myspace and tumblr themes (or neopets in my case!)
Not everyone that fooled around here went on to careers related to the website, but for kids, the draw of these webpages was that is was a very open space to experiment. Especially because no one was doing it particularly well!
Youtube was absolutely that for film directors, sketch artists, and memesters.
I would share with you one of my videos, but it's honestly PRETTY EMBARRASSING! Just think early Smosh, but a lot more wholesome.
An amateur space has the same impact that professional sports has on kids. They see people playing soccer at an incredibly high level, but can easily throw a ball in their own backyard and understands the concept of aiming for a net. (This insight actually comes from watching a Game Theory video on eSports from 7 years ago — a really deep nugget!) Creativity is encouraged through less than perfect models.
Especially as a kid! Most of the videos I adored were filmed at their parents' house, in their bedrooms.
It comes back to what I was talking about with Terry Pratchett and real life influences. I was a kid! I had a camera! I had Windows Movie Maker! I could do it all too!
Skip ahead a few years. It all changed for me when Oprah opened a Youtube channel. The environment pivoted from DIY to a marketing machine. Then followed algorithms, monetization, and YouTube eventually becoming the second most visited domain second only to Google.
The other day in a big box grocery store I saw a product named "Influencer starter kit." It's wild to me how industrialized the space has actually become.
All this to say a few things:
The internet is full of highly polished final products. But I'm trying not to sweat being an amateur. It's what was special about that time on YouTube. Many of the people I admire even still take on that spirit!
Those spaces for fooling around are still out there. Discord servers, forums, online groups.
Blogging is a pretty safe arena for this, by the way. You're separated from metrics, it's a bit more of a quiet corner (a morning breakfast table, as Trent Walton puts it.) And it feels like home.
Also, don't ever delete your videos. No matter how cringe!
Birds and Texture Sketches
Couple of my favorite birds 🦜🦃


My favorite so far — a study on texture dissections along organic forms. Completed as an asignment for Drawabox.
Major Seven Dreamy Idea
A floaty idea that hasn't quite made it into a full tune yet. 🍃
Running Cypress in CI with GitHub Actions
I recently set this site up with Cypress for a few end-to-end tests.
(An aside: last time I referred to it as an End-to-end test, but on further reflection, we're probably looking more at these being integration tests. There's no major user interaction aside from GET requests. But, I digress in semantics. Chris Coyier puts the subtle differences nicely over on his blog.)
Here's a look at a new link verification test running in Cypress locally:
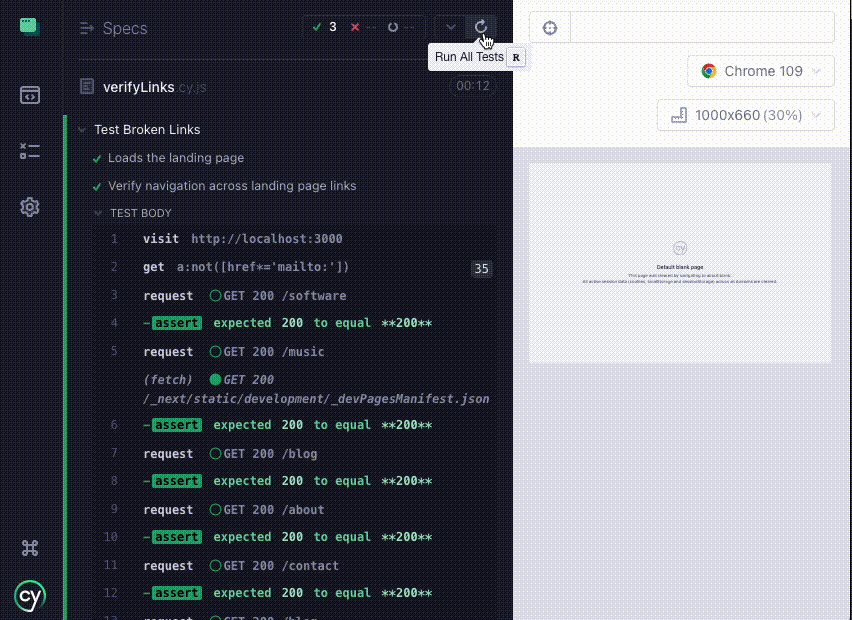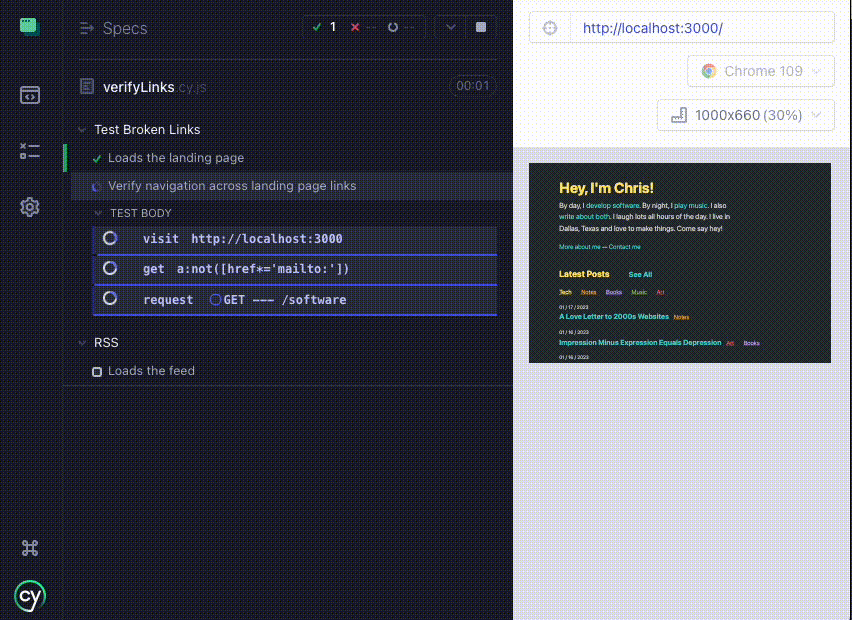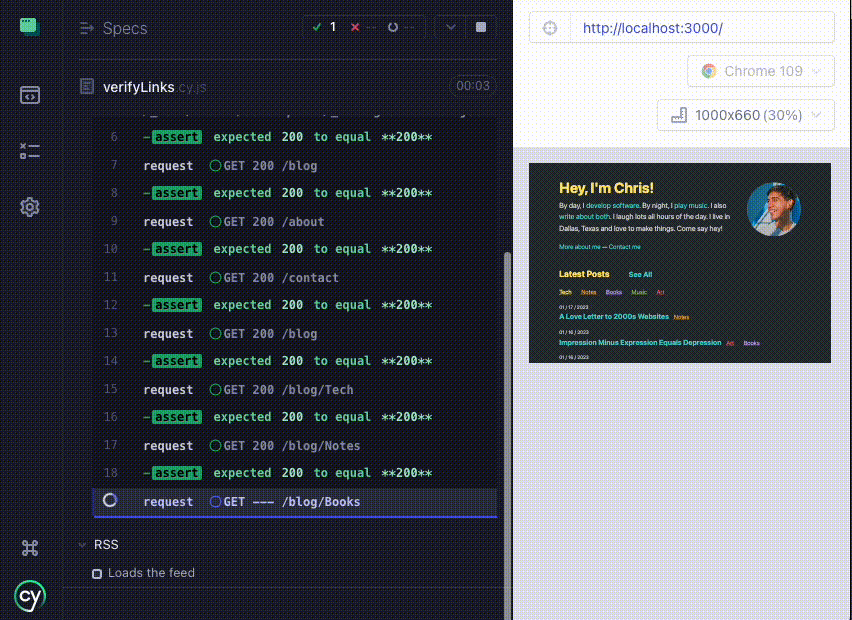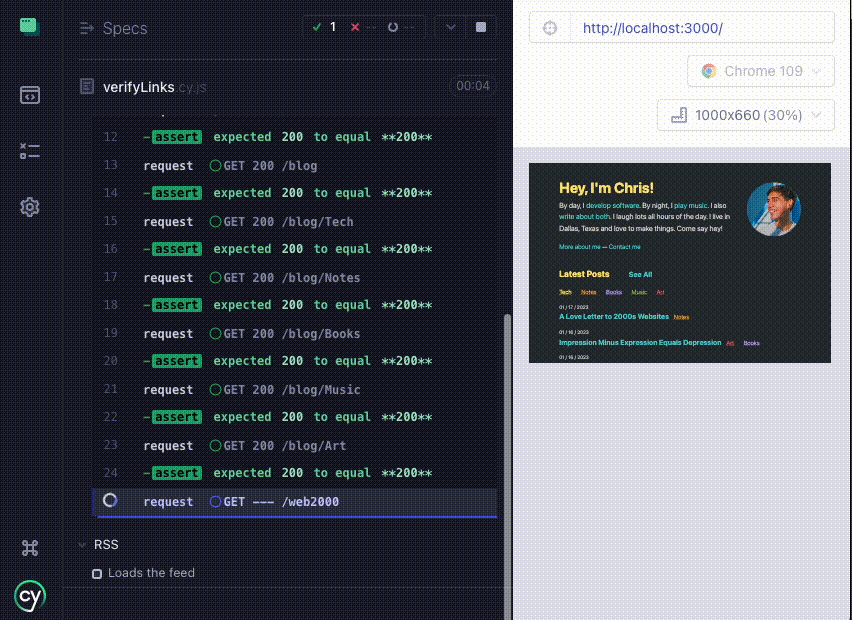
With the tests now giving me the ever so satisfying All Tests Passed notification, it's time to automate this!
Github Actions
There are many CI/CD solutions and approaches. In fact, this site is already using Vercel's Github App to automatically deploy pushes to master.
For simplicity I'm going to keep that in place, and run Cypress with GitHub Actions to automatically run my tests.
Configuration
All that's needed to add an action is to create a config file in .github/workflows.yml at the root of the repo. Here's what mine looks like:
name: Cypress Tests
on: [push]
jobs:
cypress-run:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
# Install NPM dependencies, cache them correctly
# and run all Cypress tests
- name: Cypress run
uses: cypress-io/github-action@v5.0.5 # use the explicit version number
env:
CYPRESS_BASE_URL: ${{ github.event.deployment_status.target_url }}
with:
browser: chrome
build: npm run build
start: npm start
command: npx cypress runStepping through the important parts:
Violà! Tests are now running with each push to master!

Next Steps
As it's currently setup, I'll get an email on failed tests, but Vercel is still picking up the new code and deploying it. Not an ideal solution, but since I'm a small operation here, I'm not in a hurry to add that structure.
But for the day that I do! The next step would be to remove my Vercel GitHub app from the repo. Then, I can add a deploy action as it's outlined in this post on Vercel's repo:
deploy_now:
needs: build
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@master
- name: deploy
uses: actions/zeit-now@master
env:
ZEIT_TOKEN: ${{ secrets.ZEIT_TOKEN }}The environment token can be retrieved by following these steps.